Portfolio
To access specific project details, simply click on the image associated with the corresponding project. Stay tuned for additional projects coming soon, and make use of the filters to sort projects by category.
To access specific project details, simply click on the image associated with the corresponding project. Stay tuned for additional projects coming soon, and make use of the filters to sort projects by category.
Lorem ipsum dolor, sit amet consectetur adipisicing elit. Fuga consequatur delectus porro sapiente molestias, magni quasi sed, enim corporis omnis doloremque soluta inventore dolorum conseqr quo obcaecati rerum sit non. Lorem ipsum dolor, sit amet consectetur adipisicing elit. Fuga consequatur delectus porro sapiente molestias, magni quasi sed, enim corporis omnis doloremque soluta inventore dolorum consequuntur quo obcaecati rerum sit non.
Lorem ipsum dolor, sit amet consectetur adipisicing elit. Fuga consequatur delectus porro sapiente molestias, magni quasi sed, enim corporis omnis doloremque soluta inventore dolorum consetur quo obcaecati rerum sit non. Lorem ipsum dolor, sit amet consectetur adipisicing elit. Fuga consequatur delectus porro sapiente molestias, magni quasi sed, sit amet consectetur adipisicing elit. Fuga consequatur delectus porro sapiente molestias, magni quasi sed, enim corporis omnis doloremque soluta inventore dolorum consequuntur.
During my internship at SFM Technologies, I had the opportunity to work on a
fascinating project involving Non-Intrusive Load Monitoring (NILM).
My primary focus was to implement the NILM model developed by George W. Hart,
leveraging the company's building aggregated power dataset.
Key Achievements:

During my internship at Infineon Technologies, I had the opportunity to work on a significant project titled "Design and Development of a Workflow and Related Methodologies for Validating Automotive FW and SW According to ASPICE and ISO26262 Standards."
In a rapidly evolving automotive industry where vehicles are becoming increasingly complex with millions of lines of code, the need for safety and compliance with industry standards is paramount. Infineon, a world leader in semiconductors, recognized the importance of adhering to Automotive SPICE and ISO 26262 standards to ensure the safety and quality of their products.
My internship focused on addressing the challenges faced by Infineon in monitoring and ensuring compliance with these standards throughout the development of hardware and embedded software products, which often spanned several years. To tackle this issue, I conducted a comprehensive study to identify gaps between the standards and their implementation at Infineon. Additionally, I designed and implemented an automated dashboard that consolidated project data, allowing the development and management teams to monitor project details and compliance in real-time.
This internship not only gave me invaluable hands-on experience in the automotive industry but also allowed me to contribute to the improvement of development processes that are vital for ensuring the safety and reliability of modern vehicles. I am proud to have been part of a team that worked towards reducing errors and defects, ultimately contributing to the well-being of consumers and the financial stability of automotive manufacturers and suppliers.

During my apprenticeship at Enedis AI Lab, I undertook a multifaceted role that encompassed a diverse range of responsibilities. My primary focus was on the pre-processing and feature extraction of textual and electrical load curve data. Additionally, I explored the field of natural language processing, where I actively contributed to projects such as Named Entity Recognition (NER) for the automated identification of critical information within supplier requests.
One of the noteworthy aspects of my internship was the development of machine learning models. I crafted models for both binary and multi-class classification, delving into the intriguing realm of zero-shot learning. Furthermore, I designed models for text generation and auto-completion, playing a key role in automating response generation.
To ensure the practical implementation of these models, I containerized them using Docker and facilitated their deployment in production environments. Moreover, I participated in the creation of user-friendly web interfaces, enhancing the accessibility of these AI solutions to end-users.
Throughout this enriching experience, I had the opportunity to work with a plethora of cutting-edge technologies, including Python, PyTorch, NumPy, Pandas, Scikit-Learn, RegEx, CamemBERT, BARThez, PostgreSQL, Flask, Docker, CodeCarbon, and GitLab.
In summary, my internship at Enedis AI Lab afforded me a comprehensive and diverse experience, allowing me to gain expertise in data processing, natural language processing, and machine learning model development. It also equipped me with practical skills in model deployment and interface development, contributing significantly to my professional growth.

At Aiway, I play a pivotal role in ensuring the success of our AI-driven initiatives. My primary responsibilities revolve around meticulously mapping and conducting comprehensive audits of the models developed within the organization. This crucial task involves identifying and rectifying deficiencies in data quality, as well as optimizing the entire data preparation, training, and model evaluation processes. Through my efforts, we've been able to significantly enhance the efficiency and accuracy of our AI models, ultimately leading to better-informed decision-making and improved project outcomes.
One of my core competencies lies in the development of custom metrics that empower us to evaluate semantic segmentation models with unparalleled precision. These tailored metrics have become indispensable tools for assessing the effectiveness of our AI solutions, ensuring that they meet and exceed the highest standards. In addition to metric development, I'm deeply involved in the training of cutting-edge semantic segmentation models for point clouds. Furthermore, I've spearheaded the establishment of leaderboards to continuously monitor and benchmark our models' performance, fostering a culture of innovation and excellence within the team.
Beyond semantic segmentation, I've taken on an ambitious project that involves the development of a Python library designed to adapt digital building models (BIM IFC) to accurately reflect real-world construction outcomes. This innovative library focuses on transforming point cloud data into Building Information Modeling (BIM) structures, bridging the gap between digital design and as-built reality.
To accomplish these tasks, I skillfully leverage a versatile technology stack that includes Python, Open3D, PyTorch3D, IfcOpenShell, BIMcollab ZOOM, MeshLab, Scikit-Learn, and GitLab. These tools empower me to deliver transformative solutions and contribute to Aiway's mission of advancing the intersection of AI and spatial data.
Afro Fashion Stable Diffusion is an AI model explicitly designed for African fashion. As part of our Inclusive Fashion AI (InFashAI) initiative, we aim to create datasets and AI models that better represent the diversity of the fashion universe. Using almost 100,000 images with their titles and descriptions from the African fashion sales platform Afrikrea , we fine-tuned the Stable Diffusion model v1.4. The resulting model generates more relevant African fashion items as it accounts better for African fashion features. Our model is capable of generating improved images of African fashion.
We hope this technology will help stylists, designers, and others in their creation and designing process. We are committed to creating more diverse and inclusive AI technologies.

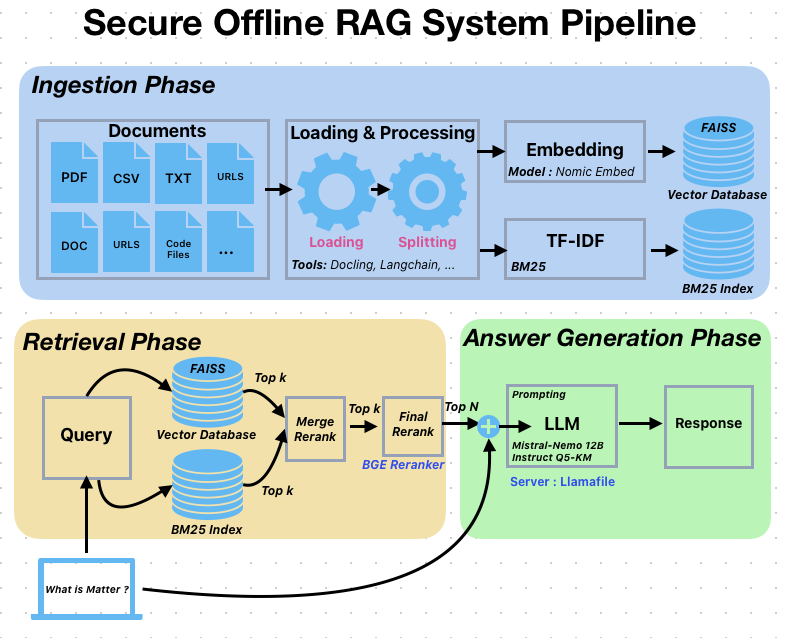
This award-winning Retrieval-Augmented Generation (RAG) system secured 1st place in the Secure RAG Challenge by UnderstandTech, demonstrating excellence in building secure, offline AI solutions with emphasis on data privacy and open-source technologies. I architected a sophisticated multi-stage pipeline that combines advanced document processing, hybrid retrieval mechanisms, and optimized language model integration. The system leverages Docling for superior PDF-to-Markdown conversion, implements a dual encoding strategy using Nomic Embed for semantic understanding and BM25 with TF-IDF for keyword matching, and utilizes FAISS vector database alongside a BGE Reranker to ensure highly relevant results. Through Llamafile integration, I achieved flexible CPU/GPU performance optimization, enabling efficient inference while maintaining resource control—all tested and optimized on hardware configurations with 32GB RAM and 8GB VRAM.
I designed the system to handle diverse content types seamlessly, supporting text documents (Markdown, PDF, CSV, HTML), multiple programming languages (Python, JavaScript, Java, C++, Go, Rust, and more), and technical documentation with intelligent parsing that preserves header hierarchies and metadata. Key technical achievements include implementing an advanced caching system for optimized performance, GPU-accelerated embeddings with automatic memory management, thread-safe LLM operations, and a configurable processing pipeline with comprehensive logging and progress tracking. The solution features a user-friendly Streamlit web interface and emphasizes practical deployment considerations, making it suitable for production environments requiring secure, offline RAG capabilities with minimal computational overhead.
The TSP Visualization App is a JavaFX desktop application designed to help children understand the Traveling Salesman Problem (TSP) through interactive visualization. This app developpement is dedicated to science education for young audiences.
The Traveling Salesman Problem is a classic optimization problem where the goal is to find the shortest path that visits a set of given points.
The project follows the Model-View-Controller (MVC) architectural pattern:
The project was developed using the following tools:

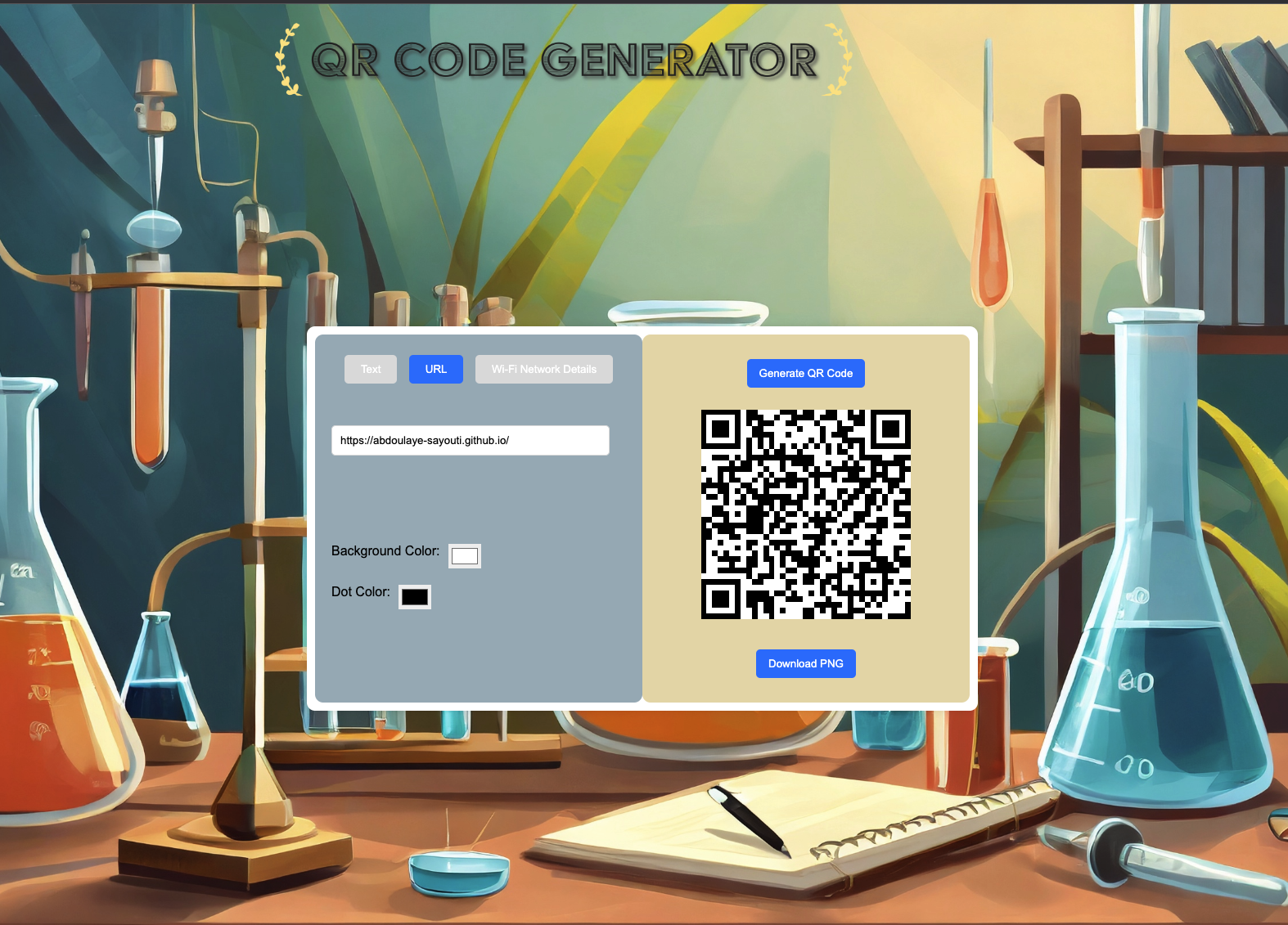
An intuitive, free and user-friendly QR Code Generator developed using HTML, CSS, and JavaScript, designed to deliver a seamless user experience. Enables the creation of QR codes from a variety of input types including Text, URLs, and Wi-Fi Network details with ease. Users are empowered with the ability to customize the QR code’s appearance by altering its color scheme and can download the generated code in a PNG format. Particularly focused on providing a straightforward, navigable UI to accommodate both tech-savvy users and digital beginners alike.
The project was developed using the following tools:
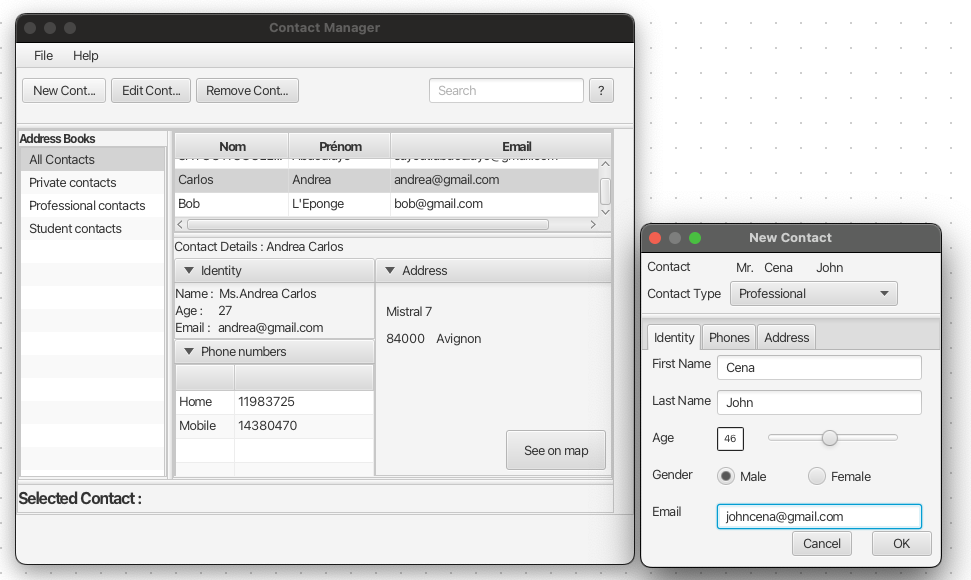
The JavaFX Address Book App is a user-friendly and efficient desktop application designed to help users manage their contact information seamlessly. This application leverages the power of JavaFX to provide an intuitive and visually appealing user interface for organizing and maintaining personal or professional contact lists.
The project was developed using the following tools:
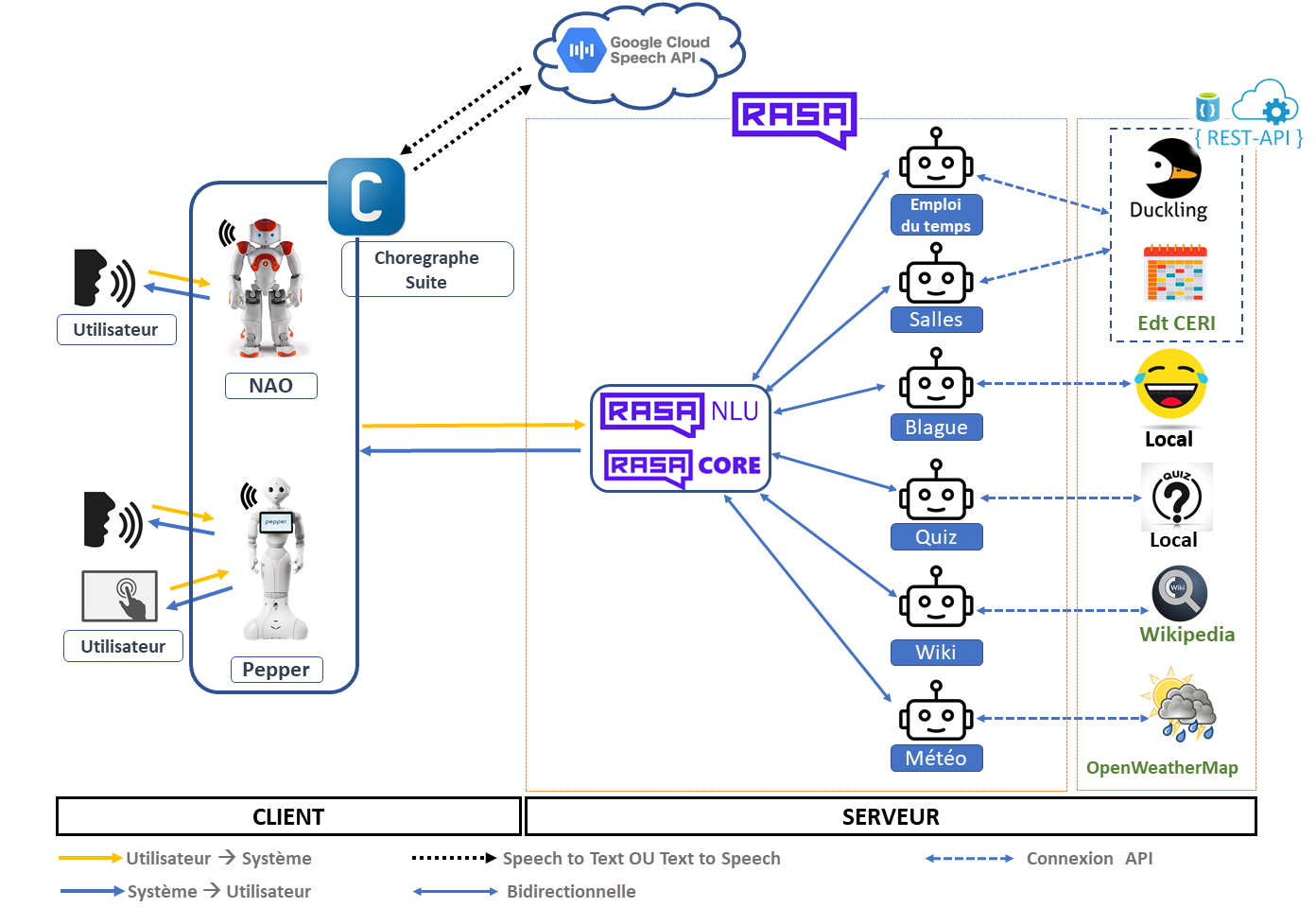
The project was developed with two of my classmates. The aim of this project is to set up a human-robot dialogue interface (vocal and visual) using the capabilities of programmable humanoid robots. Programmable humanoid robots: NAO and Pepper from SoftBank Robotics. The final solution is a developed chatbot using the RASA open-source framework and machine learning algorithms. The chatbot is then interfaced with the two robots to act as a welcome agent at the Centre d'Enseignement et de Recherche en Informatique (CERI). The bots have two main functionalities:
The project was developed using the following tools: